(別紙)
■リスク評価ツールの実施例
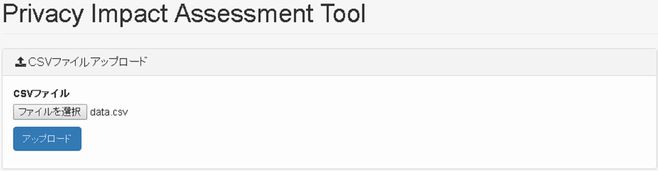
評価を行いたいデータセット(csvファイル)をアップロードします。このときレコードの分布などデータセットの特徴を抽出します(図1)。
図1:ファイルのアップロード
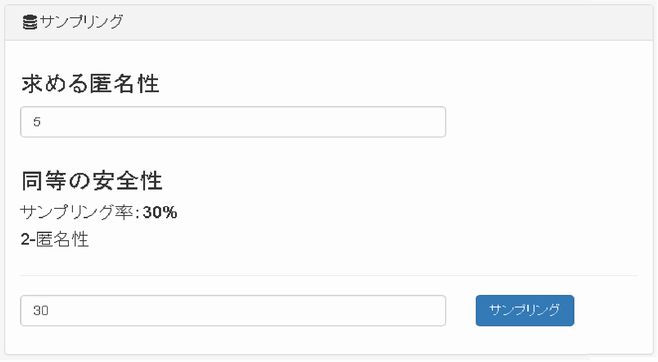
ユーザーが求めたい安全性をkの値で入力すると、それと同等の安全性を持つ匿名化手法を提案します。下記例では5-匿名化と、30%のサンプリングと2-匿名化を組み合わせたものが同等の安全性であることを示しています(図2)。
図2:匿名化手法の提案
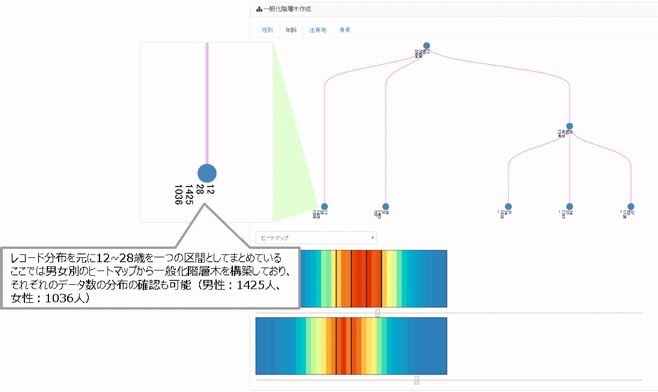
匿名化を行うために、一般化階層木(注)を作成します。一般化階層木のパターンは多様であり、この作り方によっても安全性、有用性が大きく変わります。そのため、一般化階層木の作成をアシストする機能も複数具備しております。下記例では、性別毎に分割した年齢のヒートマップを用いて、一般化階層木を構築しています(図3)。
(注)汎化のルールを決めるためのデータ構造。住所の場合、例えば、東京を一度汎化すると関東、二度汎化すると東日本へと変化するというような対応関係を定義する。
図3:ヒートマップを用いた一般化階層木の構築
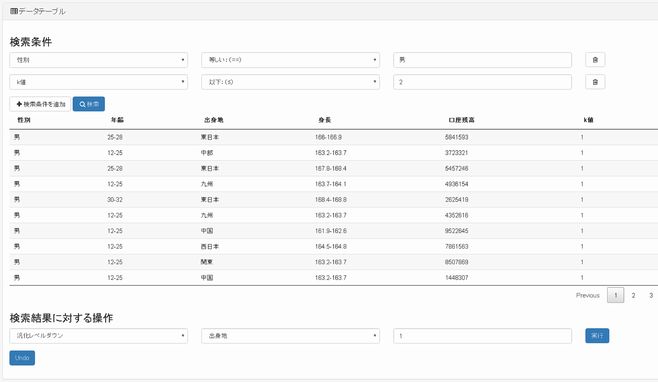
一般化階層木の作成後は、匿名化を行います。簡単な入力のみから複雑な汎化を行うことができるため、細やかな匿名化が可能となります。下記例では、「性別=男」かつ「同じ準識別子の組み合わせの数(k値)≦2」を満たすレコードに対して出身地の汎化を行っています(図4)。
図4:匿名加工処理の実施
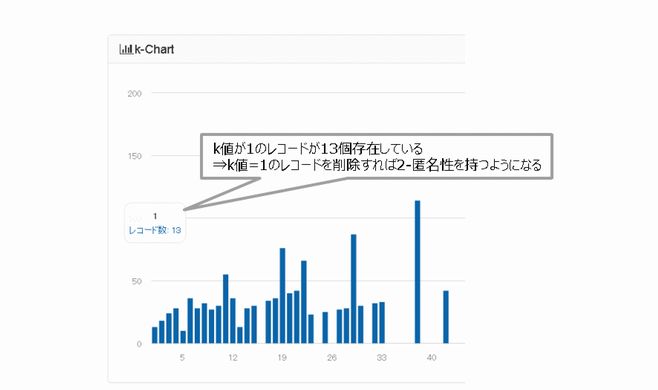
匿名加工処理を行っている間、リアルタイムで安全性の分布が確認できるため、どのような匿名加工処理を行うと、どのように安全性が変化するかがひと目でわかります。下記例では、k値が1のレコードが13個しか存在していないため、これらのレコードを削除することで2-匿名性を持つデータセットの生成が可能です(図5)。
図5:安全性の分布
※ニュースリリースに記載された情報は、発表日現在のものです。 商品・サービスの料金、サービス内容・仕様、お問い合わせ先などの情報は予告なしに変更されることがありますので、あらかじめご了承ください。